Using pgVector with SeaORM in Rust
PGVector with SeaORM in Rust
It's year 2025 and Large Language Models are all the rage, but using them indiscriminately can be costly. One technology that helps reduce redundancy and minimizes resource consumption is Vector Search.
Using vector databases, high dimensional representations of data can be stored and queried efficiently. This allows for similarity searches, clustering, and other machine learning tasks to be performed at scale, without having to use the generative services of a Large Language Model, be it on-prem or as a service, at the same rate that you would do otherwise.
Especially in the case of using AI services, sending data indiscriminately can be a strategic risk as well as cost driver.
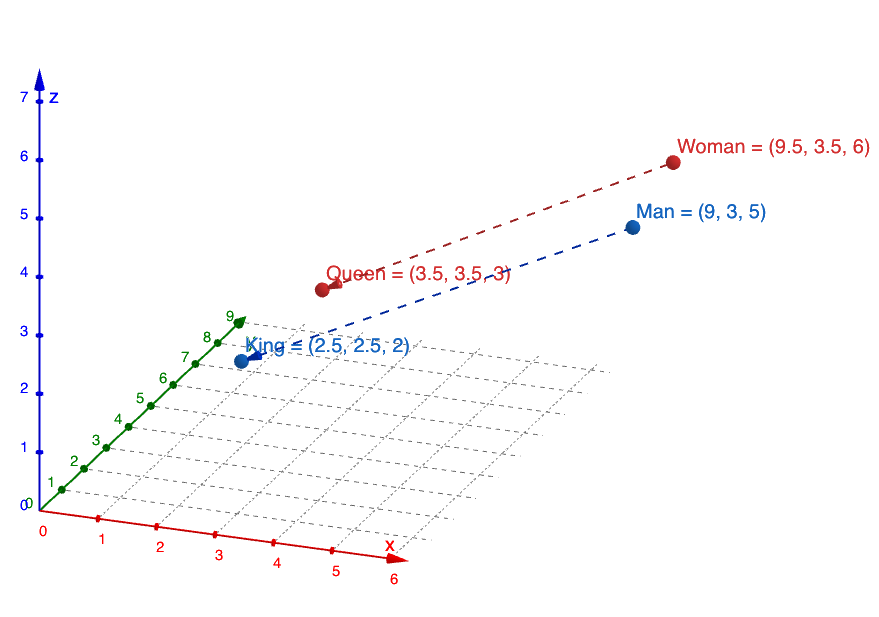
The cover image is a visualization of the intuition behind of embedding vectors, where similar concepts are grouped together in the vector space, and this further allows for interesting relationships to be observed. The ubiquitous example in this case is King – Man + Woman = Queen.
PGVector is a PostgreSQL extension that allows for vector data to be stored and queried efficiently. It enables vector operations and allows for indexing of vectors. It essentially supercharges PostgreSQL with vector operations, effectively turning it into a vector database.
SeaORM on the other hand is an ORM for Rust supporting PostgreSQL among other databases. SeaORM is an easy to use library that has gained constant traction in the Rust community. It is actively maintained, has great documentation and growing community support.
While SeaORM does not directly support vector operations, it can easily be used against a pgvector enabled database.
Preparations
We want to make this as easy as possible, so we will use Docker to start a PostgreSQL instance with pgvector installed.
A regular PostgreSQL image will not work, as it does not have the pgvector extension installed, and this is probably not something you want to handle manually.
For production workloads, you can install the pgvector extension on your PostgreSQL instance, but this is outside the scope of this article. You can also use managed PostgreSQL services that support custom extensions, including pgvector. One such service is AWS RDS, which allows for pgvector to be enabled on the PostgreSQL instances. The approach I will describe here can also be used with AWS RDS.

Go ahead and start the PostgreSQL instance with pgvector installed:
docker run \
--rm -d \
--name pgvector \
-p 5432:5432 \
-e POSTGRES_PASSWORD=postgres \
pgvector/pgvector:pg16We will use Terraform to setup the database, so make sure you have that installed. Create a provider.tf file that will contain the providers configurations. We use the postgresql provider to manage the database, including the extensions, and we use the sql provider to run migrations, that will set-up the database schema. The credentials used are the default ones and we are also using the default database.
terraform {
required_version = ">= 1"
required_providers {
postgresql = {
source = "cyrilgdn/postgresql"
version = ">= 1.25"
}
sql = {
source = "paultyng/sql"
version = ">= 0"
}
}
}
provider "postgresql" {
host = "localhost"
username = "postgres"
password = "postgres"
sslmode = "disable"
}
provider "sql" {
url = "postgres://postgres:postgres@localhost:5432/postgres"
}Create a main.tf file that will contain the database setup and the migrations.
resource "postgresql_extension" "pgvector" {
database = "postgres"
name = "vector"
}
resource "sql_migrate" "m0" {
depends_on = [postgresql_extension.pgvector]
migration {
id = "m0"
up = <<SQL
CREATE TABLE public.embeddings (
id SERIAL PRIMARY KEY,
embedding VECTOR(4)
);
SQL
down = "DROP TABLE IF EXISTS public.embeddings;"
}
}First thing that will happen is that the pgvector extension is enabled in the postgres database.
Next, the table embeddings is created. This table will store the embeddings, which are vectors of 4 dimensions. In real life scenarios, the embeddings will have much higher dimensionality, but for the sake of simplicity, we will use only 4 dimensions in this case. Note that the VECTOR type is a pgvector specific type.
To provision the database and create the table , run the following commands in the folder where you have created the *.tf files above.
This is just to make sure you are starting from a clean slate.
rm -rf \
.terraform \
.terraform.tfstate \
terraform.tfstate.backup \
.terraform.lock.hclNow, initialize the Terraform project and apply the changes.
terraform init
terraform apply --auto-approveIf you connect to the database and inspect it, you will notice some pgvector specific elements.
The prerequisites are now in place, and we can start looking at some Rust code :smiling-ferris-emoticon:.
The Code
Let us first create a new Rust project. For that we will use cargo. I am going to assume that since you are here, you already have the Rust toolchain installed.
cargo new pgvector-seaorm
cd pgvector-seaormAdd the required dependencies to the Cargo.toml file.
[dependencies]
sea-orm = { version = "1", features = ["sqlx-postgres", "runtime-tokio-native-tls"] }
tokio = { version = "1", features = ["rt", "rt-multi-thread", "macros"] }tokio is the async runtime that sea-orm uses and is ubiquitous in the Rust async ecosystem.
sea-orm is the ORM that we will use to interact with the database.
We enable the sqlx-postgres feature to be able to use PostgreSQL as the database backend. SeaORM is based on sqlx, which is a great lower level library for working with databases in Rust.
PgVector newtype
We will use a newtype to more elegantly represent the embeddings. Create a new file src/pg_vector.rs and add the following code.
use sea_orm::DeriveValueType;
#[derive(Clone, Debug, PartialEq, DeriveValueType)]
pub struct PgVector(pub Vec<f32>);Database table model
We need to define a model repsenting entities in the embeddings table. To this end, create a new file src/embedding.rs and add the following code.
use crate::pg_vector::PgVector;
use sea_orm::entity::prelude::*;
#[derive(Clone, Debug, DeriveEntityModel)]
#[sea_orm(table_name = "embeddings")]
pub struct Model {
#[sea_orm(primary_key, auto_increment = true)]
pub id: i32,
#[sea_orm(select_as = "FLOAT4[]")]
pub embedding: PgVector,
}
#[derive(Copy, Clone, Debug, EnumIter, DeriveRelation)]
pub enum Relation {}
impl ActiveModelBehavior for ActiveModel {}Most of the details and annotations are self-explanatory.
However, what is key to note is that SeaORM does not support the VECTOR type natively. Due to this, without the select_as annotation, SeaORM would not be able to correctly map to the PgVector type. To achieve this, we use the select_as annotation to tell SeaORM to cast the embedding column from VECTOR to FLOAT4[]. This will then allow SeaORM to correctly map the column to the PgVector type.
Querying the database
We will now write some code to interact with the database. Overwrite the contents of the src/main.rs file with the following code.
Establishing a connection
Some of the use statements are not in use yet, but will be.
This code simply instantiates a connection to the database.
mod embedding;
mod pg_vector;
use pg_vector::PgVector;
use sea_orm::sea_query::OnConflict;
use sea_orm::{Database, DbBackend, EntityTrait, FromQueryResult, JsonValue, Set, Statement};
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let db = Database::connect("postgres://postgres:postgres@localhost:5432/postgres").await?;
Ok(())
}Inserting data
We will now insert some data into the embeddings table.
let vectors = vec![
embedding::ActiveModel {
id: Set(1),
embedding: Set(PgVector(vec![0.1, 0.8, 0.5, 0.3])),
},
embedding::ActiveModel {
id: Set(2),
embedding: Set(PgVector(vec![0.4, 0.2, 0.7, 0.9])),
},
embedding::ActiveModel {
id: Set(3),
embedding: Set(PgVector(vec![0.9, 0.5, 0.1, 0.6])),
},
];
embedding::Entity::insert_many(vectors)
.on_conflict(
OnConflict::column(embedding::Column::Id)
.update_column(embedding::Column::Embedding)
.to_owned(),
)
.exec(&db)
.await?;Getting all data
We will now query the database to get all the embeddings.
embedding::Entity::find()
.all(&db)
.await?
.iter()
.for_each(|embedding| {
dbg!(embedding);
});You should get this output:
[src/main.rs:42:13] embedding = Model {
id: 1,
embedding: PgVector(
[
0.1,
0.8,
0.5,
0.3,
],
),
}
[src/main.rs:42:13] embedding = Model {
id: 2,
embedding: PgVector(
[
0.4,
0.2,
0.7,
0.9,
],
),
}
[src/main.rs:42:13] embedding = Model {
id: 3,
embedding: PgVector(
[
0.9,
0.5,
0.1,
0.6,
],
),
}PGVector operations
More interestingly is to use the vector operations that pgvector provides. This query gets the nearest neighbour to a given vector.
Two things are important to note here:
- The use of the
pgvectorspecific construct<->to calculate the distance between vectors. - Casting the vector to
FLOAT4[]so as to allowSeaORMto transform the data to thePgVectortype used by theembedding::Model. Again, if casting is not used,SeaORMwill not be able to use theVECTORtype.
embedding::Entity::find()
.from_raw_sql(Statement::from_sql_and_values(
DbBackend::Postgres,
r#"SELECT "id", "embedding"::FLOAT4[] FROM "public"."embeddings" ORDER BY "embedding" <-> $1::VECTOR LIMIT 1"#,
[PgVector(vec![0.3, 0.1, 0.6, 0.5]).into()],
))
.one(&db)
.await?
.iter().for_each(|embedding| {
dbg!(embedding);
});The result is:
[src/main.rs:55:13] embedding = Model {
id: 2,
embedding: PgVector(
[
0.4,
0.2,
0.7,
0.9,
],
),
}Lastly, let's exemplify how to get the distance between two vectors:
JsonValue::find_by_statement(Statement::from_sql_and_values(
DbBackend::Postgres,
r#"SELECT "embedding" <-> '[0.5, 0.8, 0.0, -0.6]' AS "distance" FROM "public"."embeddings";"#,
[],
))
.all(&db)
.await?
.iter()
.for_each(|distance| {
dbg!(distance);
});The result is:
[src/main.rs:68:9] distance = Object {
"distance": Number(1.1045361146699684),
}
[src/main.rs:68:9] distance = Object {
"distance": Number(1.7635192467093759),
}
[src/main.rs:68:9] distance = Object {
"distance": Number(1.3038404993264),
}You will notice there's no need to cast the vector to FLOAT4[] in this case, as VECTOR type columns are not selected for retrieval.
Conclusion
Using pgvector with SeaORM in Rust is a powerful combination. Only two things are needed to make this work:
- Annotate the model column referencing the
VECTORtype withselect_as = "FLOAT4[]". - Cast the
VECTORtype toFLOAT4[]when selecting a column that is of typeVECTORfor the purpose of retrieval viaSeaORM.
I have also created a supporting GitHub repository that contains the full code.